Is a Mixture of Models a Competitive Advantage?
More choice seems better, right? Turns out that is the case, but it comes with a cost, and not necessarily a monetary one.

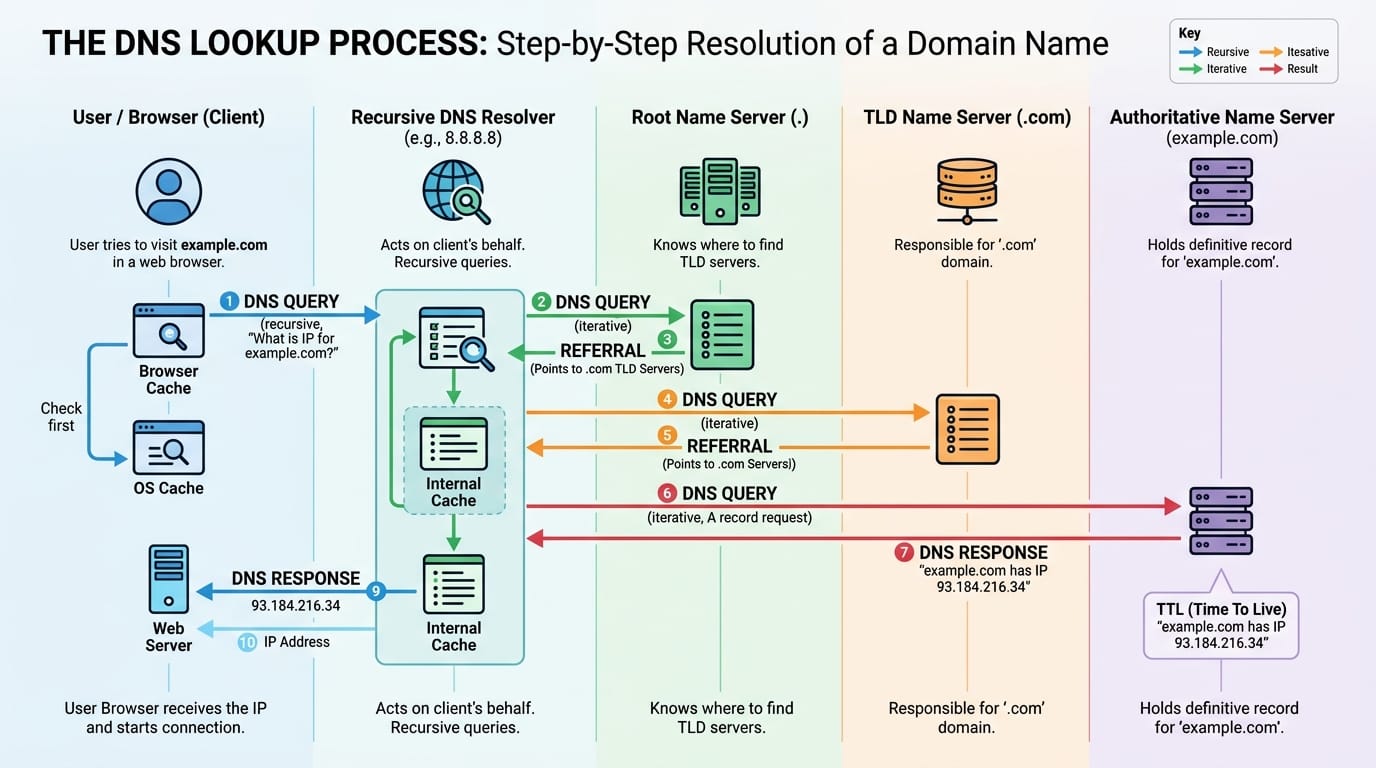
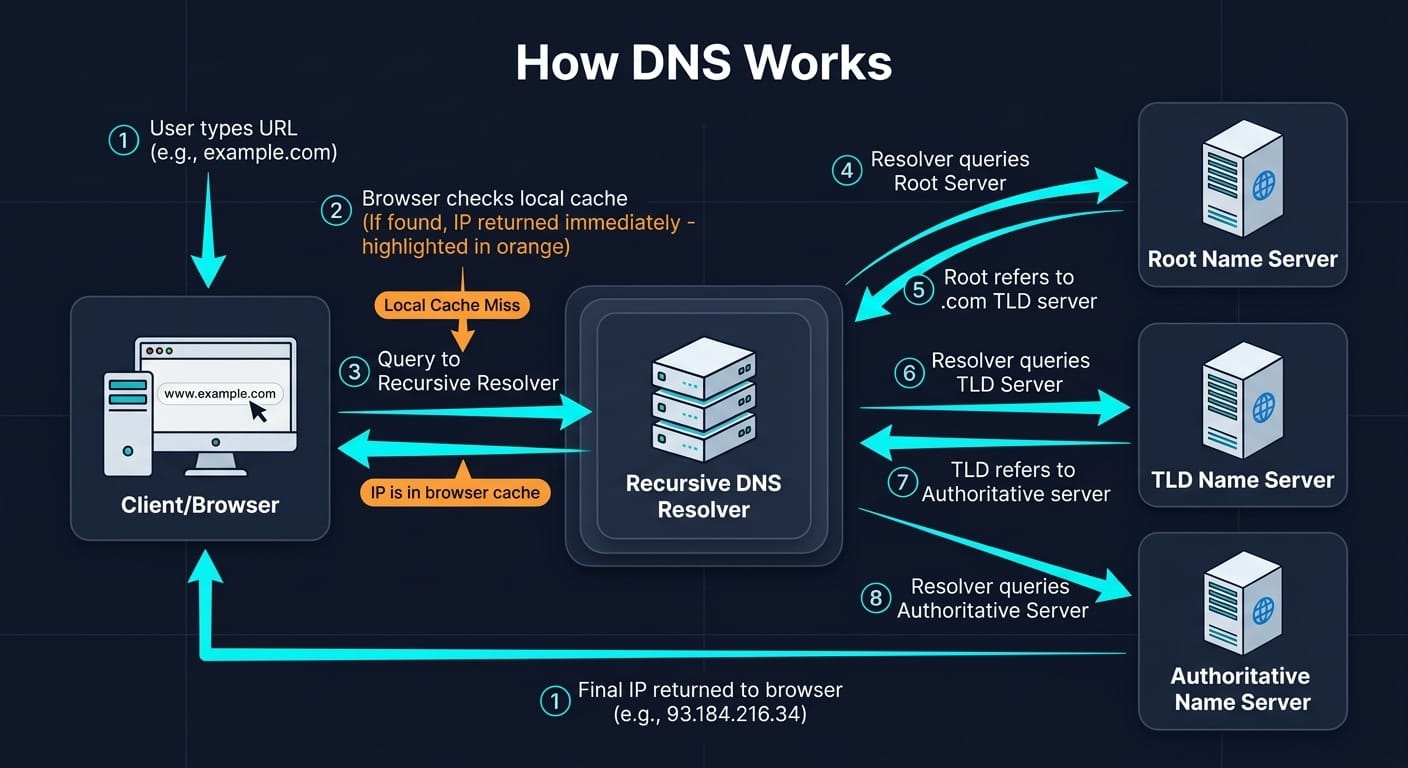
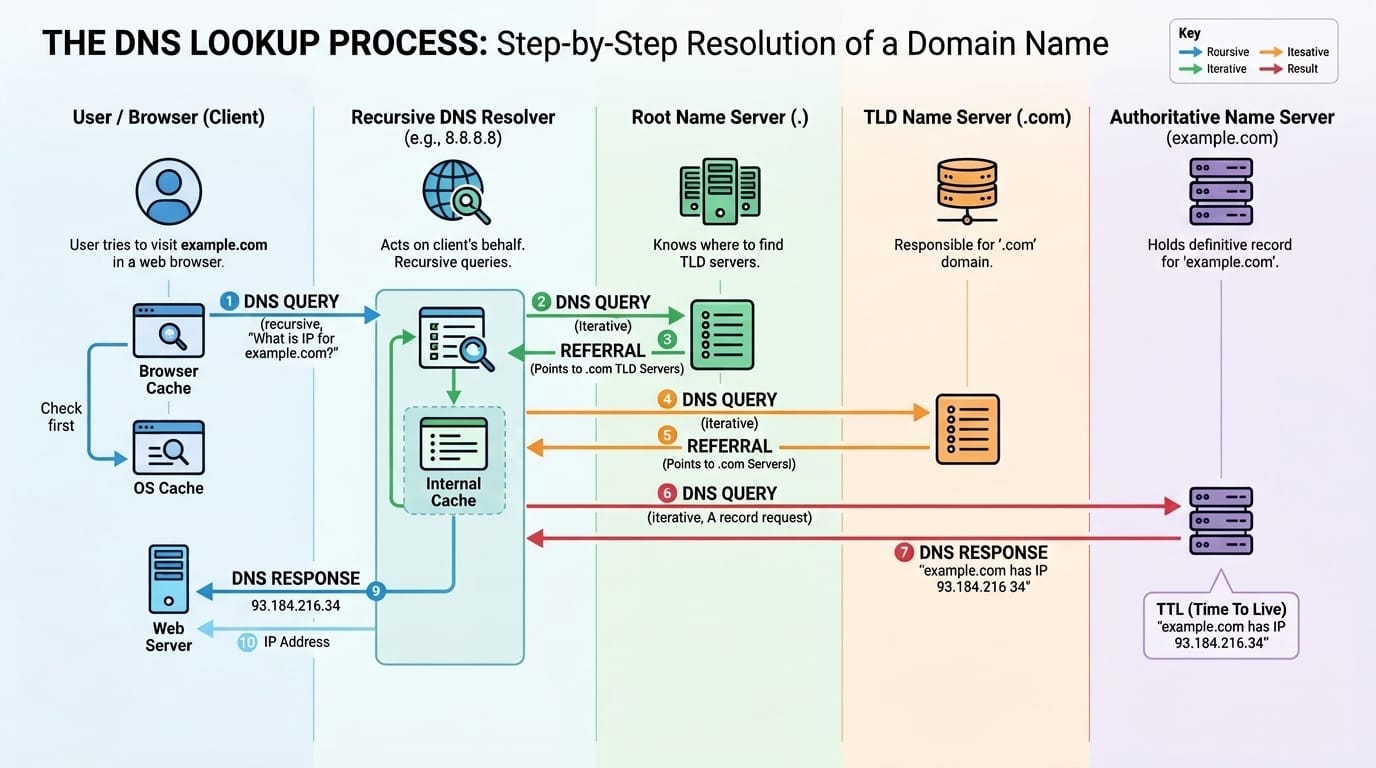
OpenAI, Anthropic, and most of Google's products only allow users to use their own frontier LLMs. Companies like Microsoft, Cursor, and Perplexity provide you the choice to use multiple models. More choice seems better, right? Turns out that is the case, but it comes with a cost, and not necessarily a monetary one. Let's explore some scenarios to figure out the magnitude of the benefit of a mixture of models.
Isolating the Mixture Effect
How much does using multiple LLMs together improve performance over using just one? This is tricky to measure because there are plenty of confounding factors that could explain away any benefit. One factor is compute. Naively calling three models instead of one means you are spending roughly three times the tokens, and more tokens is known to improve performance (via higher reasoning effort, or chain of thought). A fair comparison needs to hold total compute roughly constant. Another is prompts. Each CLI agent ships with its own system prompt and tool definitions. Of course, Claude Code, Codex CLI, and Gemini CLI all setup the API requests differently, even if the user input is the same. Thus, an improvement might be a prompting artifact rather than a mixture effect. Finally, the benchmarks need to either have reliable evaluations provided or be easy to grade to measure whether the mixture actually helped.
Humanity's Last Exam
Humanity's Last Exam is a benchmark of 2,500 questions across over a hundred subjects designed to be challenging by today's standards. Current frontier models achieve about 40-50% accuracy. The problems are short answer or multiple choice and have concrete answers that an LLM judge can easily verify. It provides a high signal for model intelligence, albeit only being an approximate proxy for actual useful work agents are currently doing. All of the agents have web search or web fetch disabled and are told to avoid using search so they cannot look up answers. Note that with CLI agents it's difficult to completely disable internet access, as they still need to be able to write code and tools, which might have external dependencies.
Hummingbirds within Apodiformes uniquely have a bilaterally paired oval bone, a sesamoid embedded in the caudolateral portion of the expanded, cruciate aponeurosis of insertion of m. depressor caudae. How many paired tendons are supported by this sesamoid bone? Answer with a number.
For this experiment, 50 problems were sampled at random from the full dataset. The baseline is straightforward: Claude Code with Opus 4.6 at medium reasoning effort is asked to solve each problem directly. The team approach splits the work into two phases. In the exploration phase, three agents each independently analyze the problem and write their thoughts to a file. Each agent is given a different persona: one uses a default system prompt, one is encouraged to be a contrarian, and the third is told to approach the problem like a top-tier professor. This controls for the possibility that simply prompting a single model with different personas is sufficient, which is an approach that is known to be reasonably effective[1]. In the solver phase, a fresh Claude Code instance receives the original question along with the three exploration files, in random order, and produces a final answer. For the single-model team, all three explorers and the solver use Claude Code with Opus 4.6. For the mixture team, the setup is the same, but the three explorer roles are randomly assigned between Claude Code, Codex CLI with gpt-5.4 at medium reasoning, and Gemini CLI with gemini-3.1-pro-preview at default reasoning. This setup allows us to control for the impacts of different system prompts, since both approaches use various personas. It also controls for the impact of increasing compute, as the single model approach is still using three different agents to first explore the problem.
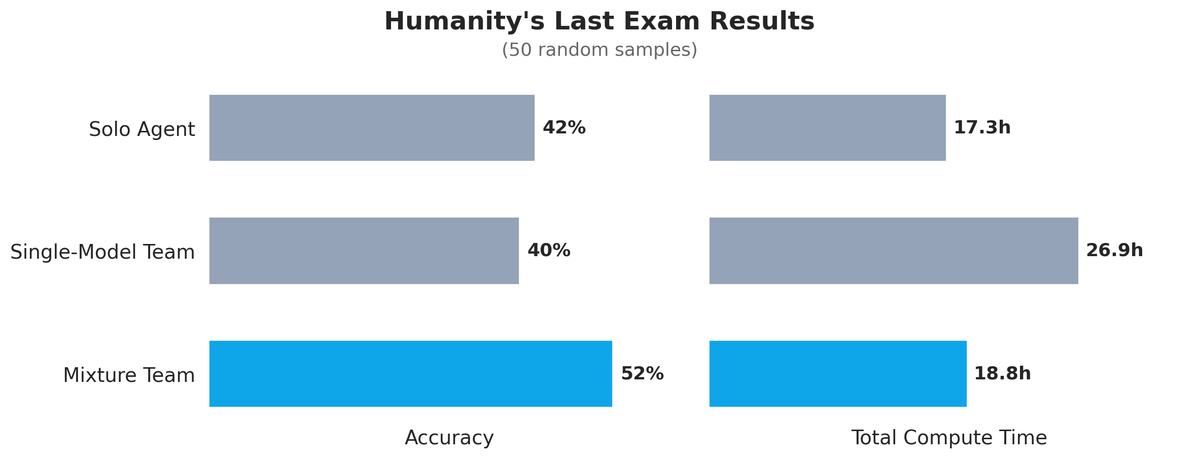
Baseline Claude got 21 out of 50 correct in about 17 hours of compute[2]. The single-model team of Claudes, despite using three explorers and taking much longer at nearly 27 hours of compute, scored 20 out of 50, slightly worse than the baseline. The mixture team got 26 out of 50 correct, a 52% accuracy rate, solving 5 more problems out of the 50! It did so in about 19 hours, only slightly more total compute time than the baseline. This can be attributed to the fact that the mixture team is asked to provide analysis, and then the solver only has to analyze and provide a final answer, whereas in the solo case, Claude got into super long reasoning chains when asked to solve the problem directly. It is interesting that when asked to solve these benchmark problems directly, the models take amounts of time that they never do in practice. Reminiscent of a present day Dieselgate...
There were 8 instances where the diverse team got the correct answer, while the solo Claude answered incorrectly. Three cases went the other way. Of those eight, half were cases where the correct analysis was the minority! In three of those cases, GPT-5.4 had the correct analysis, and Gemini was correct once. Here is one example reasoning from Claude after looking at the three analyses for a particular problem:
"Looking at the three analyses, I see a critical disagreement:
- Analysis 1: Argues for G (None of the above), citing insufficient saturation in an ultrapower over N for arbitrary topological spaces
- Analysis 2: Argues for B (Robinson's classical characterization)
- Analysis 3: Argues for B but acknowledges subtleties
The key issue is whether Robinson's characterization works in an ultrapower over N for arbitrary topological spaces. Let me verify Analysis 1's counterexample carefully."
...
"The decisive insight is that while Option B (Robinson's characterization) is the standard textbook answer for nonstandard continuity, it requires sufficient saturation in the nonstandard model. The problem explicitly specifies an ultrapower over N (limited saturation) with arbitrary topological spaces (potentially uncountable neighborhood character). The omega_1+1 -> Sierpinski space counterexample demonstrates a discontinuous map where B holds vacuously because the ultrapower over N cannot 'see' that omega_1 is a limit point."
I am not going to pretend to understand the problem or its solution, but it is fascinating to see that when presented with one correct analysis, that it notably could not derive itself, Claude is still able to pick it out and end up with the correct answer. Humanity's Last Exam is a great test of knowledge and raw problem solving, but the next experiment evaluates it on a completely different, creative dimension.
A Mixture of Models to Iterate on Infographics
Gemini models are commonly regarded as being the best for image understanding. There's a lot of anecdotal evidence for this such as StrongDM's Weather Report. To test this, this experiment measures how effectively infographics can be iterated upon via a frontier model interfacing with Nano Banana[3]. Whilst Nano Banana is doing the editing, the LLM still needs to both understand the image to know how to make it better, and have an understanding of how to effectively use Nano Banana.
The setup starts with 10 different scenarios based on infographic-builder which is a wonderful project for generating super nice infographics by one of my colleagues. For each scenario, an initial infographic is created directly using Gemini CLI's Nano Banana extension. Every original infographic then goes through three rounds of refinement. In each round, the model evaluates the image through a different lens, in sequence:
- Information Architecture and Content Accuracy,
- Visual Design and Aesthetic Cohesion
- Visual Communication Effectiveness
The agent decides whether to edit the image or leave it as-is. As a baseline, all three rounds are performed by Claude Code. For the mixture experiment, the setup is the same, but the model used in each round is randomly assigned between Claude Code, Codex CLI with gpt-5.4 medium reasoning, and Gemini CLI with gemini-3.1-pro-preview, default reasoning. In both cases the same initial image is used.
Here are some of the results I liked better for the mixture approach. The left image is the original one generated by Nano Banana directly, the middle image is the one edited by only Claude Code, and the right image is the one edited by the mixture of models.
| Initial | Single-Model Refinement | Mixture Refinement |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
And here are some of the better ones from the Claude-only approach:
| Initial | Single-Model Refinement | Mixture Refinement |
|---|---|---|
 |
 |
 |
 |
 |
 |
Out of the original ten scenarios, two of them failed to generate edits due to Codex misunderstanding the working directory and instead going up a directory and reverting back to the original image. The remaining eight received a subjective ranking based on aesthetics and quality/accuracy of the information. The mixture approach had the best average rank at 1.5 out of 3, compared to 2.125 for Claude-only editing and 2.375 for the original generations.
Data Never Tells the Full Story
Even in a world where code is becoming increasingly cheap to write, it is still not free. Leveraging multiple models comes with an implementation cost. Even whilst writing these experiments, trying to string together off the shelf agents in relatively simple ways led to tons of failures and bugs. Claude incorrectly reports cost, the Codex process randomly failed to start, and Gemini doesn't let you choose reasoning. Every hard problem and behavior that was figured out for one model provider has to be optimized for the next, and then your code becomes that much more complex. You have to manage n providers and their unique prompts, tools, API endpoints and so on. Earlier this year I built interop-router to help with this by creating one common API between Anthropic, Codex, and Gemini. It took a week or two of agent-assisted development and is only the API piece - it does not help to answer how best to prompt or create tools for each provider.
Conclusion
The takeaway is that if you are in a spot where you can build a product with multiple models, figure out ways to weave them seamlessly together. For example, plan with one model, execute with another, verify with a third. Doing it this way will not increase costs (it might even decrease costs if one of those models is cheaper than the best default). This is likely to continue to be an opportunity for the companies that have the ability to use multiple models. How long this opportunity persists as models improve remains to be seen. I think it will for the time being, even if models reach the point where they are all super intelligent. Tasks like receiving writing feedback, getting different opinions, and so forth might be harder to solve purely through prompting with just one model. Even while editing this blog, Claude vs. Gemini vs. GPT-5.4 found different and valid mistakes I made. Stay tuned.
The code for these experiments is available on GitHub
Examples of research where personas were shown to perform better: PersonaFlow, CoMM, Town Hall Debate Prompting, Dynamic Role Assignment for Multi-Agent Debate, Debate-to-Write, MetaGPT, ChatDev, AgentCoder, Expert Personas Improve LLM Alignment ↩︎
Compute time includes time the agents spent running scripts, some of which took a while or hung and had to be manually killed. Take time with a grain of salt. ↩︎
Each agent had access to Gemini CLI with the official nanobanana extension and was told to use it to edit the infographic. ↩︎