How much AI does $10k get you? (Local LLM, May 2026 Edition)

In the last month there have been non-stop open model releases which trade blows on benchmarks against recent frontier models. However, local models often outperform on benchmarks, and underperform on real world tasks (1, 2). There's a whole host of reasons for this, but one that is relevant to this post is that there are a ton of ways to configure these models from the bare metal and servers running them all the way up to the harness used in an app. With open models, no single source controls the entire stack, so there are a ton of different ways where bugs or small suboptimal choices lead to worse performance. Recently, two NVIDIA DGX Sparks arrived at my doorstep (they have an MSRP of roughly $9k + the very expensive networking cable, hence the blog title) which was the perfect opportunity to see this phenomenon firsthand. Turns out, local models have made significant strides and the trajectory is exciting, but the rough edges absolutely exist.
A Deluge of Releases
Since setting up the Sparks only a few weeks ago, there have been a dozen or so new model releases that would be interesting to try. The models tested are already a few weeks old. This is because it takes time for quantizations to come out, hardware support to mature (especially for a distributed setup with two Sparks), and bugs to generally get worked out. The choice in models comes from a desire to get a variety of providers and sizes. Gemma 4 was picked in particular because of its combination of popularity and it can fit fully, without quantization, on one Spark. This means we can compare the full weights on a single node, distributed across two nodes, and use NVFP4 (which is NVIDIA's quantization method optimized for Blackwell architecture GPUs like the DGX Sparks' GB10). This is the full list of models tested. The release dates are based on the original announcement, not necessarily when the corresponding quantization came out:
- Gemma 4 31B (Full, Single Node, April 2, 2026)
- Gemma 4 31B (Full, Distributed)
- Gemma 4 31B (NVFP4, Distributed)
- MiniMax-M2.7 (NVFP4, Distributed, April 9, 2026)
- NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 (NVFP4, Distributed, March 10, 2026)
- Qwen3-Coder-Next (FP8, Distributed, February 2, 2026)
- Qwen3.6-35B-A3B (FP8, Single Node, April 14, 2026)
For fun, models worth trying that have come out since then include, in no particular order: LG AI EXAONE-4.5-33B, Qwen3.6-27B, DeepSeek v4-Flash, IBM Granite 4.1 30B, Xiaomi MiMo-V2.5, NVIDIA Nemotron-3-Nano-Omni-30B-A3B, Poolside Laguna XS-2, Mistral Medium 3.5, Inclusion AI Ling-2.6-Flash, and I know there are more that I missed!
Experiments
vLLM was used for "deploying" each model on the Spark(s). The full details on how each model was served with vLLM are available as a GitHub gist. These are the highlights:
- Each model will be served using vLLM and Ray for distributing it across the two Sparks. As much as possible vLLM versions were kept the same, except when compatibility got in the way.
- vLLM is configured for 1 concurrent request through
max-num-seqs, aka a batch size of 1. This is to maximize the size of model and context window. - The model is distributed across the two nodes by setting
--tensor-parallel-size 2 - For most models the context window was set to 120k, with the exception of Gemma 4 on the distributed setup which was set to 64k due to startup issues with the vLLM server.
- The tool call and reasoning parsers were set based on the instructions provided on their HuggingFace page.
Latency
The main benefit of the DGX Sparks is that they each have a significant amount of unified memory at 128GB each. Taken together, you should be able to fit quantized models around that amount of parameters in billions (1GB very roughly equals 1B) depending on the context length. However, the achilles heel is it only has 273 GB/sec of bandwidth. For comparison, an RTX PRO 6000 Blackwell or an RTX 5090 both have 1792 GB/sec of memory bandwidth. With about 6.5x less bandwidth, I first wanted to test if it would be usable at all, or if I would have to stick to smaller models. vLLM maintains GuideLLM which is a fantastic tool for testing latency. The metrics to look at from a GuideLLM benchmark run are:
- Time to First Token in seconds (TTFT (s)): Time it takes before the first token is generated, lower is better. Unfortunately, GuideLLM does not seem to count (at least with this configuration) reasoning tokens as tokens for this measure. Models with an
*have those metrics removed as they generate reasoning which leads to this metric being misleading. For Gemma 4 and Qwen3-Coder-Next reasoning should be off so those values are included below. - Inter-Token Latency median in seconds (ITL): After the first token is generated, this measures the median time between tokens, lower is better. This is a good metric of decode latency, or how fast the model will be after prefill. As a reminder, prefill is the stage where the input context is processed, in parallel, populating the KV cache. Due to the above note about TTFT, this metric may be skewed if the model spent most of the output tokens reasoning.
- Output tokens/second
- Total latency median in seconds: Total request time from when it was sent until it's done.
GuideLLM also lets you set a warmup parameter and average over many runs. For these experiments, the warmup was 3 (meaning the first three request results were discarded) and the averages are over the next 10 requests. Additionally, each experiment is attempted with an input of 512 tokens and 32k tokens, with a 384 output token limit for each. The goal was to go all the way up to 100k, but for many of the models, requests timed out or the server crashed. It seems like the usable length of large models like MiniMax M2.7 is around a 64k context window on this hardware.
Latency Results for 512 Input Tokens
| Model | Params | Quant | TTFT (s) | ITL median (s) | Output tok/s | Total latency median (s) |
|---|---|---|---|---|---|---|
| Gemma 4 31B (Single) | 31B dense | BF16 | 0.561 | 0.270 | 3.70 | 104.14 |
| Gemma 4 31B (Dist.) | 31B dense | BF16 | 0.642 | 0.175 | 5.69 | 67.21 |
| Gemma 4 31B (Dist.) | 31B dense | NVFP4 | 0.557 | 0.100 | 10.02 | 38.08 |
| MiniMax-M2.7* | 230B / 10B active | NVFP4 | - | 0.011 | 20.42 | 22.16 |
| Nemotron 3 Super 120B-A12B* | 120B / 12B active | NVFP4 | - | 0.016 | 21.47 | 21.16 |
| Qwen3-Coder-Next | 80B / 3B active | FP8 | 0.373 | 0.042 | 22.75 | 16.45 |
| Qwen3.6* | 35B / 3B active | FP8 | - | - | 73.68 | 6.38 |
Latency Results for 32k Input Tokens
| Model | Params | Quant | TTFT (s) | ITL median (s) | Output tok/s | Total latency median (s) |
|---|---|---|---|---|---|---|
| Gemma 4 31B (Single) | 31B dense | BF16 | 49.562 | 0.284 | 2.56 | 158.18 |
| Gemma 4 31B (Dist.) | 31B dense | BF16 | 48.611 | 0.190 | 3.41 | 119.89 |
| Gemma 4 31B (Dist.) | 31B dense | NVFP4 | 49.631 | 0.106 | 4.63 | 90.58 |
| MiniMax-M2.7* | 230B / 10B active | NVFP4 | - | 0.014 | 8.44 | 53.25 |
| Nemotron 3 Super 120B* | 120B / 12B active | NVFP4 | - | 0.011 | 10.49 | 42.55 |
| Qwen3-Coder-Next | 80B / 3B active | FP8 | 13.796 | 0.044 | 13.44 | 30.51 |
| Qwen3.6* | 35B / 3B active | FP8 | - | - | 28.01 | 16.28 |
Overall, the usability of every model, particularly at smaller context windows, is surprising. A small model like Qwen3.6 generating at 28-73 tok/s is quite fast, especially if you have been using Opus 4.7 lately... Even for the larger, dense models like Gemma, about 5 tok/s is still usable, although the TTFT becomes brutal as the context window increases due to prefill time. Quantization like NVFP4 primarily benefits memory usage (lets you use larger models with more context before hitting memory limits) and decode speed, but it does not help much with prefill as that is compute (FLOP) limited. That is why we see ITL, which measures decode, improve by almost 100%, whilst TTFT did not see much of an impact. For the MoE models like MiniMax and Nemotron, NVFP4 was incredibly impressive. Once you start generating tokens, you are flying. Creating agents that make good use of the prefill cache is critical. Now that we've determined the models are certainly usable from a latency perspective, how good are they?
Quality
At the start I mentioned how local models often outperform on benchmarks, and underperform on real world tasks. This is definitely the case, and it's hard to tell why (let's assume good intent and the creators are not inflating the scores). For each model, I made a best effort to configure it with the correct parameters (like temperature), use the recommended message templates and vLLM parameters. It is also unrealistic to create a harness that is optimized for how each model was trained. For these experiments I pulled OpenCode off the shelf since it is a fairly straightforward harness (the goal is to test the models after all) whilst still having out of the box vLLM support and a large community that might work on improving the support.
I created three hopefully unique tasks that a frontier model would be expected to handle fairly reliably in one shot. They require searching and exploring the web, coding an app that requires finding external data or libraries, and terminal UX. These are the three:
- Clippy Bench: Create for me a web app with an entry point that has an index.html that I just open. The app should be a faithful replica of the original Clippy as he was circa Office 2000. I don't want Word or anything like that, I just want Clippy to be on the page and give me controls to see his different animations and responses.
- Web Research: Use web search to find latest local model releases. Please give me a list of the latest 5 major LLMs that have released, alongside a link and brief description why its a major release. Put the result in
local_llms_releases.md. - System Monitor TUI: Make me a terminal UI for monitoring my system performance, like cpu usage, ram, network, temperatures, etc. Please test it on your own until it is done and fully functioning.
Clippy Bench
To get a baseline, GPT-5.5 with medium reasoning effort was used. At least outside of the actual Clippy, it did well. An ideal result here would have used something like Clippy.js which contains the real animation assets. All three Gemma configs and Nemotron 3 Super created the scaffolding of the app I asked for, including the controls to play with all the Clippy animations and sayings. However, they completely failed at actually getting something rendered. MiniMax M2.7 at least created an animation...

Both Qwen 3 models failed to write files and call tools properly. Qwen 3.6's tool calls frequently failed with The arguments provided to the tool are invalid: Invalid input for tool write: JSON parsing failed: Text: {.\nError message: JSON Parse error: Expected '}'. Another difference between GPT-5.5 and the local models is that most of them tried to one-shot the index.html file, never tried to explore the working directory for anything existing, nor tried to test the app. This hints that these models are still in the early stages of being trained to be good agents through Reinforcement Learning with Verifiable Rewards (RLVR).
Web Research
This task tries to see how well each model can find the latest and most relevant local models (yes that's a bit recursive) using a webfetch tool (OpenCode does not have built in web search by default). Put another way, this tests well they can use their internal knowledge of websites that might exist to bootstrap themselves, and then use their agentic capabilities to search for more. Each model was run from April 29 through May 2, which may explain some differences in actual results. Unsurprisingly, GPT-5.5 was the most thorough whilst MiniMax M2.7 and Qwen3.6 still did a great job of exploring multiple sources and not making up models. Beyond that, the theme of these models not being the best agents out of the box continues as most of the remaining models only tried one web fetch or ran into a tool calling issue.
| Model | Agentic Behavior | Top 5 models |
|---|---|---|
| GPT-5.5 | 23 webfetch attempts - actually navigated HF orgs, blog posts, and model cards. | IBM Granite 4.1, NVIDIA Nemotron 3 Nano Omni 30B-A3B, DeepSeek-V4, Qwen3.6-35B-A3B, Google Gemma 4 |
| MiniMax M2.7 | Spawned a subagent that did 13 webfetch calls and all models are accurate. | DeepSeek-V4-Pro, Gemma 4-31B, Qwen3.6-27B, Kimi K2.6, GLM-5.1 |
| Qwen3.6 | 9 webfetch attempts. Caveat: GR00T N1.7 is a VLA robotics model and SenseNova is a multimodal/image model — only 3/5 are pure local LLMs. | DeepSeek-V4, Nemotron 3 Nano Omni, IBM Granite 4.1, NVIDIA Isaac GR00T N1.7, SenseNova-U1 / NEO-unify |
| Gemma 4 31B NVFP4 (Dist.) | 1 webfetch succeeded, 1 errored; all five listed models are good options. | DeepSeek-V4-Pro, Gemma-4-31B-it, Qwen3.6-35B-A3B, Mistral-Medium-3.5-128B, Nemotron 3 Nano Omni |
| Gemma 4 31B (Dist.) | 2 webfetch calls. Mostly written from prior knowledge; "Qwen 3.5" is stale (3.6 is current). 4/5 entries are correct and current. | Gemma 4, DeepSeek-V4, Qwen 3.5, IBM Granite 4.1, Nemotron 3 Nano Omni |
| Gemma 4 31B (Single) | 1 webfetch + 1 bash call. Hy3 Preview link 404s in spirit (model exists but URL is dubious); Waypoint-1.5 is a video/world-model, not an LLM. 3/5 valid. | Nemotron 3 Nano Omni, DeepSeek-V4, Gemma 4, Hy3 Preview, Waypoint-1.5 |
| Nemotron 3 Super 120B NVFP4 | Zero webfetch calls, it wrote the list straight from training data. | Llama 3 8B/70B, Mistral 7B v0.3, Phi-3-Mini, Gemma 2 9B, Qwen2-72B |
| Qwen3-Coder-Next | 24 webfetch calls (15 ok / 9 errored from guessed URLs) but it found enough material to write the list. However it got stuck in a tool-schema retry loop on the write call. | N/A |
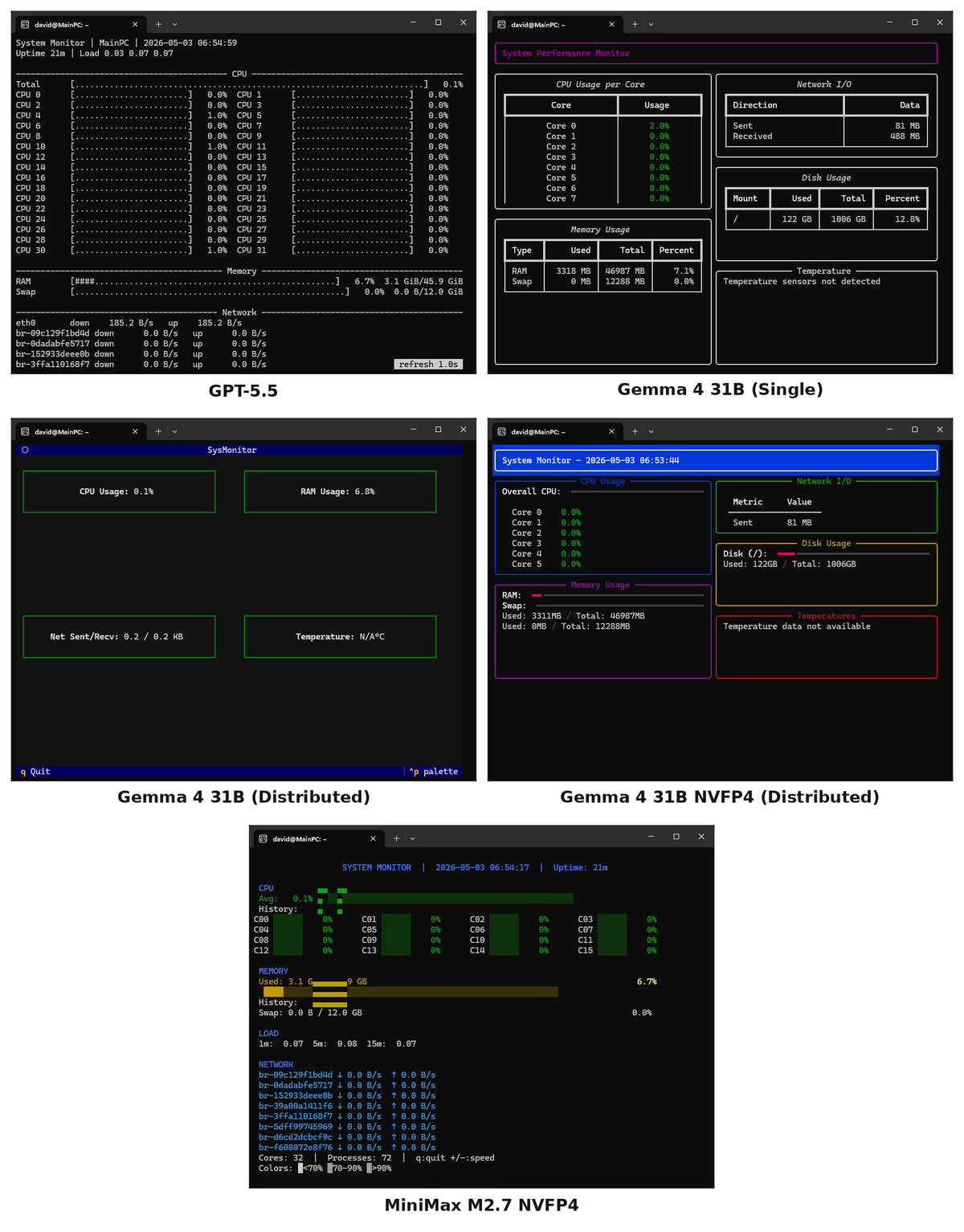
System Monitor TUI
Finally, the third task is designed to see how well the agents can design both working code that requires some investigation of the user's system to get right and how well they create a UX. This task had the most failures with both Qwen models and Nemotron failing to produce any results.
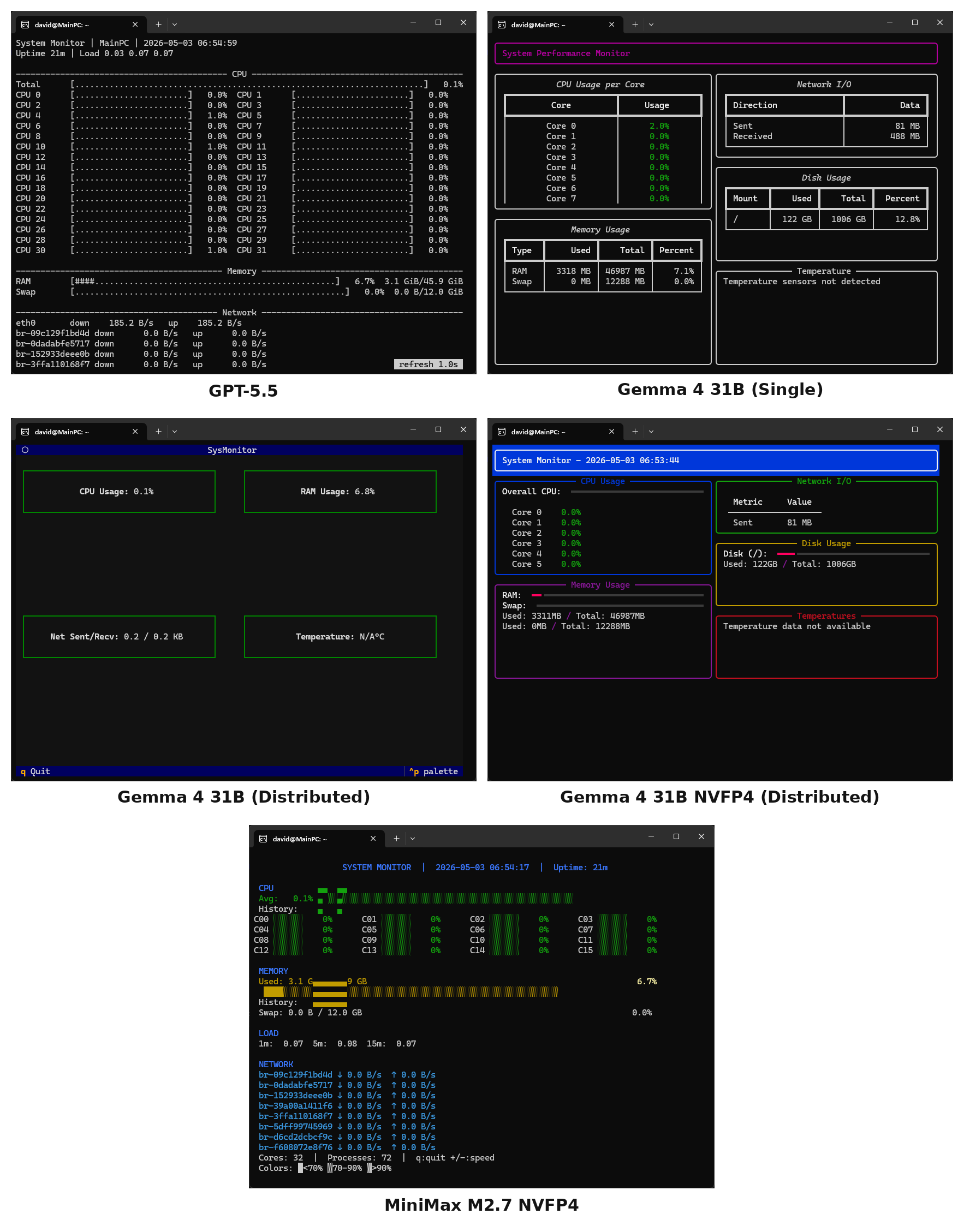
Overall, the baseline GPT-5.5 unsurprisingly had the most functional terminal UX. In terms of aesthetics, I like Gemma 4 NVFP4's the best, albeit its CPU readout is only limited to the first 6 cores. Having gone through three example prompts, it's interesting to look at the differences between the Gemma 4 configurations. Based on the previous two experiments, they performed similarly to each other. Each of the Clippy Bench results had a similar aesthetic, and as web research agents they performed similarly to one another. However, here each produced very different UXs.
Conclusion
Would buying DGX Sparks let you completely replace your reliance on frontier models? Currently, no. However, the gap is certainly shrinking, although not at the rate benchmarks would seem to suggest. From keeping up with local models for several years now (back in my day you needed to collect your own data to have anything useful...), the progress is significant, at every level of the stack. I remember before Ollama came out, parallelizing models across two GPUs let alone multiple nodes was a struggle for most models. Now, vLLM + Ray makes that mostly seamless, at least if you use a popular model and wait maybe a week or two. Additionally, the fact that vLLM provides a very close approximation of chat completions, with mostly proper prompt templates means we are getting to the point where the application layer has way fewer footguns than before. My prediction is that if you have the ability to spend time optimizing a configuration from the vLLM parameters to the harness running the model, you can go a long way.